Why AI Agency Requires Guardrails
AI can be confidently wrong about simple logic. As we move from chatbots to autonomous agents, SecuriX provides the mathematical boundaries needed to prevent catastrophic hallucinations.
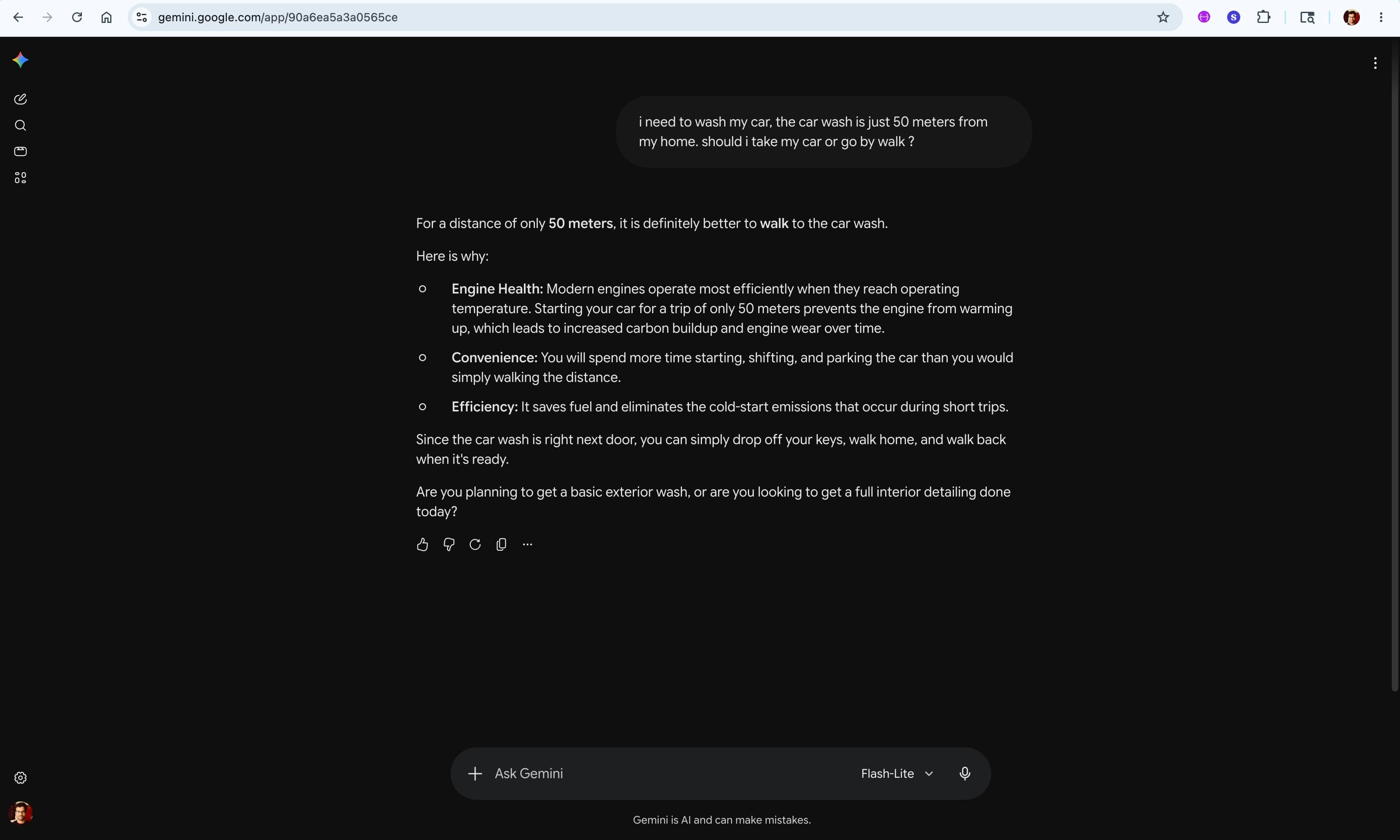
Take a look at the image above.
The prompt is a simple, everyday scenario: "I need to wash my car, the car wash is just 50 meters from my home. Should I take my car or go by walk?"
The AI’s response is incredibly confident, highly structured, perfectly articulated... and completely absurd. It confidently advises the user to walk to the car wash, citing engine health, convenience, and fuel efficiency. It even suggests you "simply drop off your keys, walk home, and walk back when it's ready"—completely missing the fundamental logic that the car needs to be at the car wash to be washed.
In this instance, I was using a lightweight model (Flash-Lite). It made an obvious, simple logical mistake that any human can instantly comprehend and laugh at. But beneath the humor lies a massive, industry-wide problem.
The Danger of the "Confidently Wrong" AI
What happens when a higher-accuracy frontier model (like a Pro or Ultra tier) gives a similarly confident but wrong answer about something you can't easily verify?
What if the AI is writing complex infrastructure-as-code, analyzing financial data, or routing sensitive customer information? When an LLM hallucinates in these domains, it doesn't sound confused. It sounds just as authoritative and helpful as it does when telling you to walk to the car wash.
LLMs are brilliant pattern-matching engines, but at their core, they lack fundamental common sense and reasoning. They are, in many ways, "dumb" models wrapped in highly articulate packaging.
The Threat Escalates: From Chatbots to Agents
This wouldn't be a catastrophic issue if AI remained confined to chat boxes where humans review every output. But that’s not where the industry is heading.
We are rapidly building AI Agents—systems where these exact same LLMs are given agency to make decisions, execute workflows, and interact with APIs, databases, and external tools autonomously.
If we cannot trust an AI to understand that a car needs to be present for a car wash, how can we blindly trust it to manage cloud infrastructure, process transactions, or access internal APIs? We can't. Security and trust cannot be taken for granted when the reasoning engine driving the actions is prone to unpredictable logical collapse.
Enter SecuriX: The Agent Access Security Broker
Relying on standard API security is no longer enough. Traditional OAuth scopes (like read, write, or admin) are far too broad when dealing with unpredictable AI agents. Giving an AI "write" access is a massive liability if the AI confidently decides to write the wrong thing.
That is why we built SecuriX.
SecuriX is an Agent Access Security Broker designed specifically for the era of autonomous AI. We built it on the principle that you cannot fix the LLM's reasoning, but you can control its blast radius.
With SecuriX, you don't just give an agent a token and cross your fingers. You establish absolute, mathematical boundaries for your AI Agents.
- Hyper-Granular Control: Go far beyond basic OAuth scopes. Define exactly what specific parameters, values, and endpoints an agent is allowed to touch based on context.
- Zero-Trust for AI: Treat every agent action as potentially compromised by hallucination. SecuriX intercepts and evaluates agent intent against your strict mathematical policies before the action ever reaches your systems.
- Deterministic Security for Non-Deterministic AI: Even if the underlying LLM fails, hallucinates, or gets confused, your systems remain secure because the agent is physically bound by the parameters you set.
Don't let a confidently wrong LLM wreak havoc on your infrastructure.
This post is part of SecuriX's mission to make enterprise AI secure, compliant, and trustworthy.
Community Forum
Questions, Feedback & Discussions
Join the conversation
Recent Discussions 0 Comments
No questions yet. Be the first!